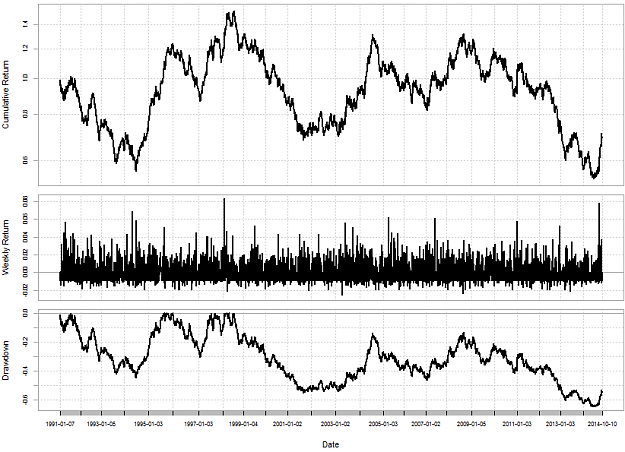
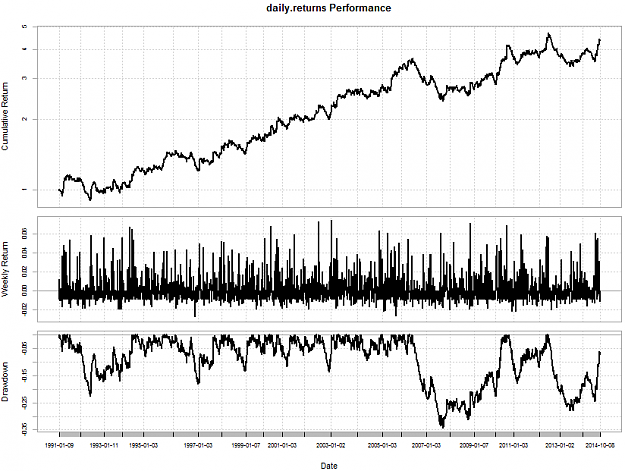
Hello fellow traders,
I am starting this thread hoping to share with you some of my developments in the field of machine learning. Although I may not share with you exact systems or coding implementations (don't expect to get anything to "plug-and-play" and get rich from this thread) I will share with you ideas, results of my experiment and possibly other aspects of my work. I am starting this thread in the hopes that we will be able to share ideas and help each other improve our implementations. I will start with some simple machine learning strategies and will then go into more complex stuff as time goes by. Hope you enjoy the ride!
algoTraderJo
I am starting this thread hoping to share with you some of my developments in the field of machine learning. Although I may not share with you exact systems or coding implementations (don't expect to get anything to "plug-and-play" and get rich from this thread) I will share with you ideas, results of my experiment and possibly other aspects of my work. I am starting this thread in the hopes that we will be able to share ideas and help each other improve our implementations. I will start with some simple machine learning strategies and will then go into more complex stuff as time goes by. Hope you enjoy the ride!
algoTraderJo